AI ethics for present & future

Professional physicists who investigate the first three minutes or the first microsecond no longer need to feel shy when they talk about their work. But the end of the universe is another matter… the striking thing about these papers is that they are written in an apologetic or jocular style, as if the authors were begging us not to take them seriously. The study of the remote future still seems to be as disreputable today as the study of the remote past was thirty years ago.
AI ethics (a family of fields including ‘Fairness, Accountability, & Transparency in ML’, ‘robot ethics’, ‘machine ethics’, and ‘AI law’) is awash with money and attention following the last decade’s enormous progress in AI systems’ performance. Just at my own university, Bristol, I count 5 researchers who have begun on this topic, on aspects like the ethics of self-driving vehicles in dangerous situations and the ethics of emotionally responsive robots, including carers, pets, and lovers.
In addition, parallel work focusses on a technology which does not yet exist: artificial general intelligence (AGI), that is, a system which could do anything a human can do, and maybe more. The issues around such a technology are quite different from the short-term issues with present pattern-matching AI systems. If they were realised, such systems could transform society through the automation of almost all labour, including the scientific and engineering labour which is so often the limiting factor in economic progress, and could even carry a risk of accidental human extinction (‘existential risk’).
Call this trend ‘AGI safety’. It has been increasing in prominence, and some of the most respected CS researchers now take the idea seriously, including Stuart Russell, the author of the most prominent textbook in AI.
If the two trends were marked only by a division of labour, there would be no problem: both scales are important, and both merit careful research. However, there appears to be a degree of animosity and very little co-operation between the two clusters of research.
People talk past each other here. Elon Musk, Lord Martin Rees, and other famous figures have weighed in on existential risk from advanced AI: as a result, popular discussion of the issue focusses on rebutting informal versions of the longtermist argument. If you’ve encountered this debate, it’s probably only the sensational form, or that plus the trivial counter-sensational pieces.
In fact, a growing minority of technical AI experts are openly concerned with the long-term impact. But when AI ethicists do acknowledge AGI safety, it is only by reference to figures outwith technical AI: the industrialists Elon Musk and Bill Gates, the philosopher Nick Bostrom - if we’re lucky and the interlocutor isn’t instead a static image of the T-800 robot from Terminator. The foil is never Turing Award winners Yoshua Bengio or Judea Pearl, Stuart Russell, or the prominent deep learning researcher Ilya Sutskever.
This sort of division is nothing new; as Dyson notes above, the tension between verification and speculation, direct evidence and extrapolation, short-run and long-run importance plays out in many fields. Academia is in general content to stick to the facts and the present context, and so to leave futurism to popular writers beyond the pale.
(There is actually a small literature on this very question, mostly taxonomies of disagreement and pleas for co-operation: Cave, Stix & Maas, Prunkl & Whittlestone, Krakovna.)
I think part of this is down to failures of communication, and part down to academia’s natural, often helpful pre-emptive dismissal of weird ideas. Let’s try and patch the first one.
Why on earth might we worry about AGI?
It seems odd for scientists to not only speculate, but also to act decisively about speculative things - for them to seem sure that some bizarre made-up risk will in fact crop up. The key to understanding this is expected value: if something would be extremely important if it happened, then you can place quite low probability on it and still have warrant to act on it.
Consider finding yourself in a minefield. If you are totally uncertain about whether there’s a buried landmine right in front of you - not just “no reason to think so”, you genuinely don’t know - then you don’t need direct evidence of it in order to worry and to not step forward.
The real argument is all about uncertainty: advanced AI systems could be built soon; they could be dangerous; making them safe could be very hard; and the combination of these probabilities is not low enough to ignore.
When you survey technical AI experts, the average guess is a “10% chance of human-level AI (AGI)… in the 2020s or 2030s”. This is weak evidence, since technology forecasting is very hard; also these surveys are not random samples. But it seems like some evidence.
We don’t know what the risk of AGI being dangerous is, but we have a couple of analogous precedents: the human precedent for world domination, at least partly through relative intelligence; the human precedent for ‘inner optimisers’, unexpected shifts in the goals of learned systems. Evolution was optimising genetic fitness, but produced a system, us, which optimises a very different objective (“fun; wellbeing”); there’s a common phenomenon of very stupid ML systems still developing “clever” unintended / hacky / dangerous behaviours.
We don’t know how hard alignment is, so we don’t know how long it will take to solve. It may involve hard philosophical and mathematical questions.
One source of confusion is the idea that the systems would have to be malevolent, intentionally harmful, to be dangerous; Nick Bostrom’s much-misunderstood ‘paperclip maximiser’ argument shows one way for this to be untrue: when your AI system is a maximiser, as for instance almost all present ‘reinforcement learning’ AI systems are, then bad effects can (and do) arise from even very minor mistakes in the setup.
Another involves equating intelligence with consciousness, missing that the AI notion of ‘intelligence’ is based on mere capacity for clever behaviour, and not any thorny philosophical questions of subjectivity or moral agency. This sidelines the very large (and for all I know valid) body of work from phenomenology criticising the very idea of machine consciousness.
It’s not that the general idea is too extreme for the public, or world government. One form of existential risk is already a common topic of discussion and a core policy area: the possibility of extreme climate change. (But, while that risk is also marked by uncertainty, animosity, and distrust, this conflict is mostly outside academic boundaries.) And this follows the broad-based opposition to nuclear proliferation, perhaps the first mass movement against x-risk in history.
What might be wrong with taking the long-term view?
Humans aren’t very good at forecasting things more than a couple years ahead. To the extent that a given long-termist claim depends on precise timing, it isn’t possible to pull off.
Weird ideas are usually wrong, and sadly often say something about the person’s judgment in general.
Most gravely, if resources (funding, popular and political attention) are limited, then long-termism could be a distraction from current problems. Or worse, counterproductive, if we did short-term harm to promote an unsure longterm benefit.
What might be wrong with taking the short-term view?
The long-run is much larger than the short-run, and could, all going well, contain many, many more people. On the assumption that future people matter at all, their well-being and chance to exist is the largest moral factor there can be; and even in the absence of this assumption, the premature end of the current generation would also be an extreme tragedy. Future people are the ultimate under-represented demographic: despite nice moves in a handful of countries, they have no representation.
Our choice of timeframe has intense practical consequences. From a short-term view, technology has many risks and only incremental benefits. But in the long run, it is our only hope of not dying out: at the very latest, because of the end of the Sun’s lifespan.
The worry about counterproductive work from the section above applies equally to short-termism. It would be quite a coincidence if picking the thing which is most politically palatable, which improves matters in the short-run was also the thing that helped us most in the long-run. One example of a short-term gain which could have perverse long-term effect is the present trend towards national or (bloc) AI strategies in the pursuit of local (zero-sum) economic or military gain, which could easily lead to an AI ‘arms race’ in which safety falls by the wayside. That said, there are plenty of opportunities which seem robustly good on all views, like increasing the transparency of AI.
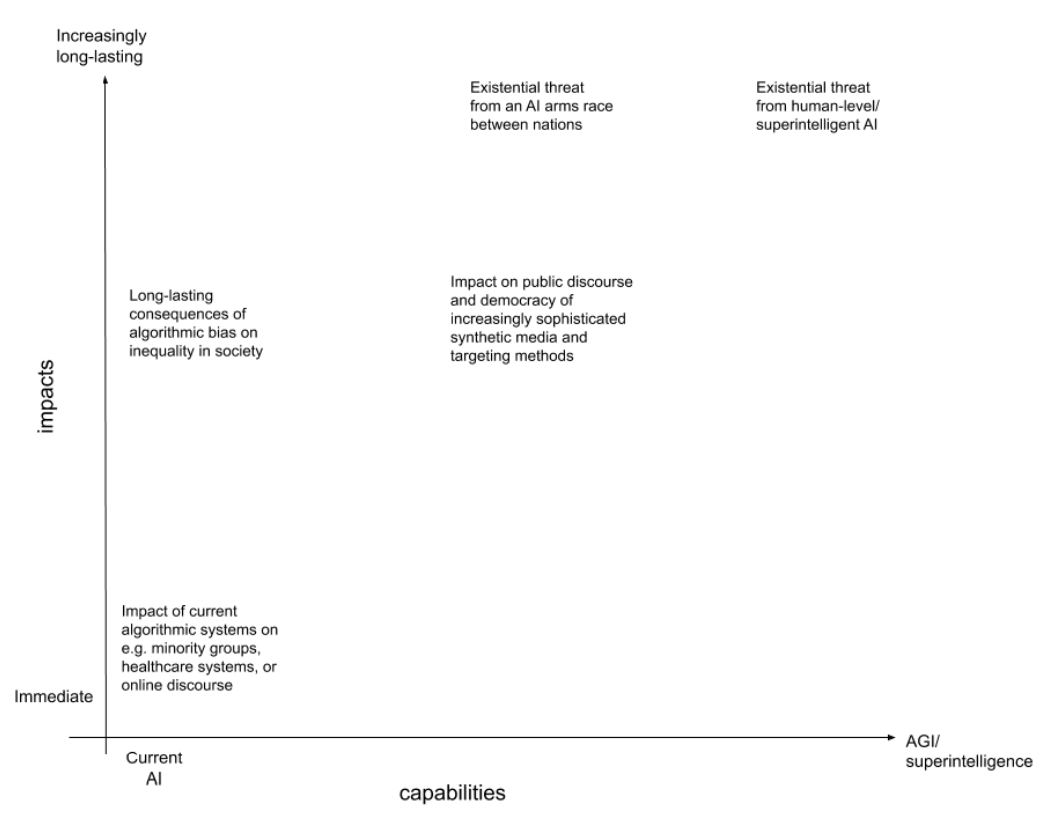
Sketch of a unified ethics of AI from Prunkl & Whittlestone.
Ultimately it’s not a binary matter and there’s no need for jostling. The figure above shows how to consider all of AI ethics on the same page, as a matter of degree, and encourages us to consider all the impacts.
Returning to the epigram from Dyson: there is hope. Since 1979, respectable work on the end of the universe has flourished. There remains a great deal of uncertainty, and so an array of live contradictory hypotheses - and quite right too. (For instance, Dyson’s own early model was obsoleted by the discovery that the cosmic expansion is accelerating.) There is no antipathy between physicists studying the cosmic birthday and those working on the cosmic doomsday - and quite right too. Perhaps we can repeat the trick with AI safety. There are few places it is more important to avoid factional disdain and miscommunication.
What moral assumptions are you making?
On the object level, views which can ignore existential risk include: People with incredibly high confidence that extinction will not happen (that is, well above 99% confidence); people with incredibly high confidence that nothing can be done to affect extinction (that is, well above 99% confidence); avowed egoists; people who think that the responsibility to help those you’re close to outweighs your responsibility to any number of distant others; people with values that don’t depend on the world (nihilists, Kantians, Aristotelians, some religions); absolute negative utilitarians or antinatalists; deep ecologists.
On the second level, perhaps one assumption is that 'academia should do good'. (Not only good, and not by naively optimising away the vital role intellectual freedom and curiosity play in both pure and socially beneficial research.) Academia does not in general allocate its vast resources with the intention of optimising social benefit. In 2012 the philosopher Nick Bostrom noted that 40 times as many scientific papers had been published on the topic of a single type of beetle than on the topic of human extinction. (The situation has improved a bit since then, in no small part because of Bostrom.)
If you're so smart, why ain't you mainstream?
Also, academia is conservative, in the sense that it pays almost all its attention to the past and present, and in the sense that it overweights probability. Also incrementality.
Short-term bias resulting from naive empiricism and the need to maintain respectability.
Biblio
- David Buchanan. 'No, the robots are not going to rise up and kill you', 2015.
- Oren Etzioni. 'No, the experts don’t think superintelligent AI is a threat to humanity', 2016.
- Allan Dafoe and Stuart Russell. 'Yes, we are worried about the existential risk of artificial intelligence',2016.
- Luke Muehlhauser. 'Reply to LeCun on AI safety', 2016.
- Anders Sandberg. 'The five biggest threats to human existence', 2014.
- Kelsey Piper. 'Why Elon Musk fears artificial intelligence', 2018.
- Martin Rees. 'Astronomer Royal Martin Rees: How soon will robots take over the world?', 2015.
- Stephen Cave and Sean OhEigeartaigh. 'Bridging near-and long-term concerns about AI'. Nature Machine Intelligence, 1(1):5–6, 2019.
- Charlotte Stix and Matthijs Maas. 'Crossing the gulf between‘near-term’ and ‘long-term’ ai policy: Towards an incompletely theorized agreement', 2020.
- Carina Prunkl and Jess Whittlestone. 'Beyond near- and long-term: Towards a Clearer Account of Research Priorities in AI Ethics and Society', AAAI/ACM Conference on AI, Ethics, and Society, Feb 2020.
- Viktoriya Krakovna. 'Is there a trade-off between immediate and longer-term ai safety efforts?', 2018.
- Gavin Leech. Existential risk as common cause.
- Nick Bostrom. Existential risk prevention as global priority. Global Policy, 4(1):15–31, 2013.
- Freeman J. Dyson. Time without end: Physics and biology in an open universe. Rev. Mod. Phys., 51:447–460, Jul 1979.
- ACM conference on fairness, accountability, and transparency. 2020.
- Geoff Keeling, Katherine Evans, Sarah M Thornton, Giulio Mecacci, and Filippo Santoni de Sio. Four perspectives on what matters for the ethics of automated vehicles. Automated Vehicles Symposium, pages 49–60. Springer, 2019.
- Teresa Scantamburlo, Andrew Charlesworth, and Nello Cristianini. Machine decisions and human consequences. Algorithmic Regulation, page49–81, Sep 2019
- Christopher Burr and Nello Cristianini. Can machines read our minds? Minds and Machines, 29(3):461–494, 2019.
- Stuart Russell.Human Compatible: Artificial intelligence and the problem of control. Penguin, 2019.
- Kate Crawford and Ryan Calo. There is a blind spot in ai research.Nature, 538(7625):311–313, 2016.
- David Krueger. 'A list of good heuristics that the case for AI x-risk fails, 2019.
- AI Impacts. 'AI timeline surveys', 2017.
- Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. Risks from learned optimization in advanced machine learning systems, 2019.
- Viktoriya Krakovna. Specification gaming examples in AI, 2018.
- Toby Ord. The Precipice: existential risk and the future of humanity,2020.
- Gregory Lewis. 'The person-affecting value of existential risk reduction', 2018.
- Christian Borggreen. 'AI fortress europe?', 2020.
- Yun Wang et al. Current observational constraints on cosmic doomsday. Journal of Cosmology and Astroparticle Physics, 2004(12):006–006, Dec 2004.