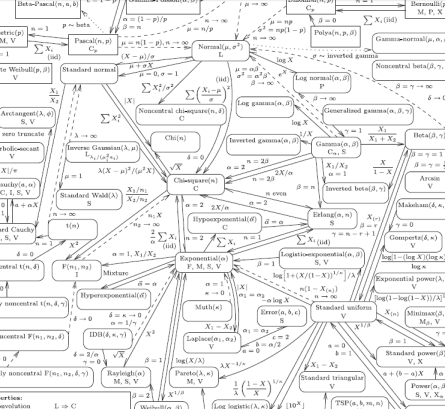
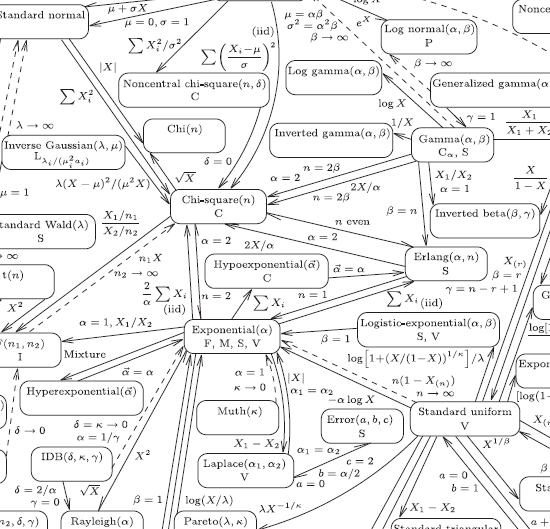
Data Science FAQ
Data Scientist: Person who is worse at statistics than any statistician & worse at software engineering than any software engineer.
What is data science?
It's a trendy way of saying 'statistical programming'.
OK, that's a bit of a stretch: data science is statistical programming that focusses on newly feasible methods for getting answers out of annoyingly large piles of data. (So, SAS work isn't said to count.) 8
We can define a data scientist in a black-box manner, as follows:
That ^ is vague; here's a breakdown of the actual tasks involved:
OK, that's a bit of a stretch: data science is statistical programming that focusses on newly feasible methods for getting answers out of annoyingly large piles of data. (So, SAS work isn't said to count.) 8
Is it a bullshit fad?
Not exactly. All, and I mean all of its insights come straight out of academic statistics, computer science, and dropout hacker lore. But just because something's made of other things doesn't mean it isn't real, that it isn't a valuable permutation.
(I grant you that only half of the excitement is due to these methods, the other half being a truckful of marketing hype.)
"Data science" is a silly name for a few reasons: because all statisticians apply scientific methods to data, and have done for a hundred years; because all programming is programming on data; because the actual job has much more data munging and rote scripting in it than it has experimental science.
(I grant you that only half of the excitement is due to these methods, the other half being a truckful of marketing hype.)
"Data science" is a silly name for a few reasons: because all statisticians apply scientific methods to data, and have done for a hundred years; because all programming is programming on data; because the actual job has much more data munging and rote scripting in it than it has experimental science.
Distinguishing analysts and data scientists
Data analysis is an art, in Knuth's sense:
and thus so is data science. 1 But it isn't cool to call yourself a data analyst, for some reason. 4
Here's an attempt: you want a data scientist, and not the similar data analyst, when:
Science is everything we understand well enough to explain to a computer. Art is everything else we do.
and thus so is data science. 1 But it isn't cool to call yourself a data analyst, for some reason. 4
Here's an attempt: you want a data scientist, and not the similar data analyst, when:
- When the data is too big for Excel.
- And then when the data is too big for SAS.
- When the data is in the wrong format for the tool
- When the data's quality is uncertain
- When the data does not have a natural outcome variable.
Why now?
- The underlying cause of most of it is the data deluge - we collect millions of times more data, basically for free. This deluge leads to all the distinctive features:
- Distributed computing, because the dataset doesn't fit in one computer's RAM.
- Sudden great performance, because it turns out that scaling your sample size gives a qualitative change for some domains (“Unreasonable Effectiveness of Data”). Same algorithms as the 60s sometimes!
- Unprecedented aggregations, means a market in data. Huge potential value in scraping and extracting unstructured sources. Acxiom is a $1bn company, for just one example; though Google is probably the pre-eminent example.
- Data products (FitBit; restaurants, friends, jobs; credit ratings; health)
(And the web and IoT are the cause of that.) - Distributed computing, because the dataset doesn't fit in one computer's RAM.
- Unsupervised machine learning allows for cheap use of the much greater volume of data which isn't annotated with a neat output label (and so can't be used for supervised training).
- Cognitive automation: we have recently been able to automate high-level things which used to require skilled humans: trading decisions, media recommendations, fine art, maybe even hypothesis generation: i.e. creativity!
- Demand for real-time summary of these new datasets means a sudden investment in stream processing algorithms and frameworks (which were previously not a very efficient use of industrial computer scientists).
A Strange Loop
We can define a data scientist in a black-box manner, as follows:
- learner: an inductive program that takes in example data and outputs a model.
- model: a static program that takes examples and outputs predictions.
- data scientist: a pretentious inductive program that takes in data and a vague problem, and outputs a learner and some good hyperparameters. 9
That ^ is vague; here's a breakdown of the actual tasks involved:
The Data Science Process
Prep
1. Domain analysis
What does this vague request really mean?
- Metric choice - How will we judge success?
- Tool choice
- Abstraction from business to data
- Abstraction from data to learner and models
- Output type. Real-time?
2. Data collection
What evidence exists? What can I use?
3. Data cleaning
How to handle flawed data?
This isn't a deep skill so much as a bag of tricks, like:
See also data wrangling and munging.
This isn't a deep skill so much as a bag of tricks, like:
- The outliers dilemma
- Missing data imputation
- Bad data
- Encoding categoricals
- Identifying measurement bias
- Clever anonymisation in a world where everyone can be sniffed out.
See also data wrangling and munging.
4. Exploratory analysis
What is the data like? What jumps out?
- Descriptive: location (Inspect the distribution of target, )
- spread (box plot, scatter plot, check for outliers)
- association (Pairwise distribution plots; What correlates with what?)
- Comparative:
- Classification: plot the data with label-coloured points
Modelling
5. Feature engineering
Which parts are useful?
Or, column curation. The terminology for FE hasn't settled down yet - that is, the following terms are actually not disambiguated in common usage - but here's what a mature language might arrive at:
Getting ideas. A mixture of research and guesswork. We can use the following 3 bit code to classify your ideas for features:
(An applied epistemology.)
Dimensionality reduction: reduce number of variables by combining them
10
Or, column curation. The terminology for FE hasn't settled down yet - that is, the following terms are actually not disambiguated in common usage - but here's what a mature language might arrive at:
- Feature engineering: the manual design of inputs for your learner. Consists in
- Feature generation: finding all potentially relevant variables.
- Feature selection: choosing the most predictive features.
- Feature extraction: deriving predictive, low-dimension, non-redundant features from variables. 401
1. Feature generation
Getting ideas. A mixture of research and guesswork. We can use the following 3 bit code to classify your ideas for features:
| Relevant | Measurable | Considered | |
| Include these features | Y | Y | Y |
| Drop these features | N | Y | Y |
| Look for proxies | Y | N | Y |
| Whose idea was this? | N | N | Y |
| Why we do research | Y | Y | N |
| Think, then proxy | Y | N | N |
| Averted waste | N | Y | N |
| Nobody cares | N | N | N |
(An applied epistemology.)
2. Feature selection
How to pick the best ones from your shortlist.
Why should I select features?
- For generalisability (out-of-sample accuracy): Reducing the number of features can reduce overfitting.
- interpretability: to understand the underlying process (via features' relationship to the output variable).
- efficiency: providing faster (and so cost-effective) predictors
Feature selection checklist
from Guyon and Elisseeff (2003):
Do you have domain knowledge? If yes, construct a better set of “ad hoc” features.
Are your features commensurate? If no, consider normalizing them.
Do you suspect interdependence of features? If yes, expand your feature set by constructing conjunctive features or products of features, as much as your computer resources allow you.
Do you need to prune the input variables (e.g. for cost, speed or data understanding reasons)? If no, construct disjunctive features or weighted sums of features (e.g. by clustering or matrix factorization).
Do you need to assess features individually (e.g. to understand their influence on the system or because their number is so large that you need to do a first filtering)? If yes, use a variable ranking method; else, do it anyway to get baseline results.
Do you need a predictor? If no, stop.
Do you suspect your data is “dirty” (... has a few meaningless input patterns and/or noisy outputs or wrong class labels)? If yes, detect the outlier examples using the top ranking variables obtained in step 5 as representation; check and/or discard them.
Do you know what to try first? If no, use a linear predictor. Use a forward selection method with the “probe” method as a stopping criterion or use the 0-norm embedded method. For comparison, following the ranking of step 5, construct a sequence of predictors of same nature using increasing subsets of features. Can you match or improve performance with a smaller subset? If yes, try a non-linear predictor with that subset.
Do you have new ideas, time, computational resources, and enough examples? If yes, compare several feature selection methods, including your new idea, correlation coefficients, backward selection and embedded methods. Use linear and non-linear predictors. Select the best approach with model selection.
Do you want a stable solution (to improve performance and/or understanding)? If yes, subsample your data and redo your analysis for several “bootstraps” .
Types of feature selection
- Filters. Score and rank each possible feature. (e.g. Univariate evaluation followed by ordering according to a criterion like RMS.) Typical filters treat features as independent; they thus return correlated features, and thus give no treatment of interactions.
e.g. Chi-squared test, information gain, correlation coefficient. - Wrappers. Picking features as a search problem. Of course, the possible subsets grow exponentially with set size. So there’s a nasty opportunity for overfitting.
1) pick an algorithm for selecting features. e.g. stepwise regression, best-first, forward/backward passes.
2) pick a criterion or filter to decide if an output set of features is good.
Compare a great many subsets with other subsets.
e.g. recursive feature elimination. - Embedding. Find the best features as you construct the final model. e.g. Random forests do feature selection as part of their construction. The most common kind of embedding is regularisation: constrained optimization, to bias the constructed model toward lower complexity (that is, fewer coefficients).
e.g. LASSO, Elastic Net, Ridge Regression.
3. Feature extraction
Dimensionality reduction: reduce number of variables by combining them
10
6. Model building
What structure will answer the question?
- Parameter tuning
- Ensemble construction
- Model selection
- Identify constraints
- Training - tune parameters
- Validation - tune hyperparameters
- Testing - *avoid* tuning
- Interpretation
- Evaluation - How good is this model? Under conditions? Experiment design to make causal sense.
7. Criticism
Go back. How many forking paths have you taken? Is your sample distribution really exactly the same as the population's? What about rare events? Do you have any right to talk about causality here? Relax all assumptions. Ablate.
Use
8. Communication
What result? What predictions? What claims?
9. Deployment
How will this be used? Who will use it?
Create business rules
Create business rules
GOTO 1. Feedback
Use the data from the deployed model to iterate the model.
ABSTRACT SOME MORE
Really your job is not coding or being able to read formulae or knowing where to find data without any anti-scraping measures: your job to optimise the difficult tradeoffs of using computers to optimise things. You're a computer economist, not much of a scientist.
- Bias / Variance. After a point, you can minimise underfitting or overfitting, not both.
- Accuracy / Interpretability. For some tasks, you can't have optimal performance while still being able to comprehend the final weights.
- Easy Training / Optimality. An instance of The Iron Triangle: 'You can pick two of: fast, cheap, optimal'.
- Space / time. You can use more data or spend less runtime.
- Natural signal / Balanced classes. In classification, you often want to train the model to recognise differing classes equally well, even if one is rarer. There are a few ways to do this, but one of them is just to use fewer examples of the common class.
- Full signal / Validation. You can train on all the available data or you can know if what you're doing is any good. This one we can defeat, with the bootstrap.
Skillset (for unicorns)
Hard to beat the exhaustive list in Harris et al (2013). (Though it covers the things you'd expect a whole data science team to have: )
- Classical statistics (general linear model, ANOVA)
- Bayesian statistics (MCMC, BUGS)
- Simulation (discrete, agent-based, continuous)
- Spatial statistics (geographic covariates, GIS)
- Temporal statistics (forecasting, time-series analysis)
- Surveys and Marketing (multinomial modeling)
- Visualization (statistical graphics, mapping, web-based data‐viz)
- Distributed data (Hadoop, MapReduce)
- Structured data (SQL, JSON, XML)
- Unstructured data (noSQL, text mining)
- Data manipulation (regexes, R, SAS, web scraping)
- Systems administration (*nix, DBA, cloud tech.)
- Frontend programming (JavaScript, HTML, CSS)
- Backend programming (Java/Rails/Objective C)
- Algorithms (computational complexity, CS theory)
- Graphical models (social networks, Bayes networks)
- Machine learning (decision trees, neural nets, SVM, clustering)
- Analysis (linear algebra, real analysis, calculus)
- Optimization (linear, integer, convex, global)
- Science (experimental design, technical writing)
- Business (management, business development, budgeting)
- Product development (design, project management)
Predecessors
Similar roles have been played in the past by jobs like expert system designer, decision support developer, knowledge discovery engineer, predictive analytics guy, business intelligence analyst, data miner, and big data engineer, with varying levels of rigour and bullshit. The quant developer, in finance, is basically the same thing but with far less variance in skill level.
A more honest name for data scientist would be analytics developer, but hey we all got to make a living. The best you can say for us is, at least we don't claim that our poky little logistic regressor is An Artificial Intelligence. (...)
A more honest name for data scientist would be analytics developer, but hey we all got to make a living. The best you can say for us is, at least we don't claim that our poky little logistic regressor is An Artificial Intelligence. (...)
Data science to define data science
By surveying people with the job title "data scientist" and then clustering the data, Harris et al. split "data scientist" into four real jobs:
Many, many articles act as if all DS jobs were data researcher jobs; this is the root of the constant HN catfighting about whether you need to know e.g. postgrad linear algebra before starting, let alone before applying.
Answer: data researchers obviously need to; the others, not so much. The ineliminable need is for decent coding skills. Maybe people take that need as too obvious to mention, but I've seen actual DS job applications which fail to mention programming once.
- Data researcher: A postgrad statistician. Writes new algorithms, builds proof-of-concept ensembles, writes analysis libraries, disseminates.
- Data developer: Machine learning engineer. Application builder.
- Data businessperson: A knowledgeable interface between technical and non-technical people. Doesn’t code: steers modelling approach.
- Data creative: Bit of everything. Heavy on visualisations? 6
Many, many articles act as if all DS jobs were data researcher jobs; this is the root of the constant HN catfighting about whether you need to know e.g. postgrad linear algebra before starting, let alone before applying.
Answer: data researchers obviously need to; the others, not so much. The ineliminable need is for decent coding skills. Maybe people take that need as too obvious to mention, but I've seen actual DS job applications which fail to mention programming once.
Alternative partition
You can also split data scientists by how well they understand the detail. This is surprisingly easy to operationalise:
I bet this ordering correlates with the performance of the models they build (r^2 > 0.4). But Kaggle don't have a financial interest in studying this.
- Can use libraries to build models
- Can implement the algorithms themselves
- Can invent new algorithms
I bet this ordering correlates with the performance of the models they build (r^2 > 0.4). But Kaggle don't have a financial interest in studying this.
Do I need a Master's degree to get a data science job?
The 2013 O'Reilly survey of self-described data scientists found 70% of respondents holding a Master's. 5 Unless you are highly skilled already, or unless your target company are enlightened, it could be hard. You should be able to start as an analyst and work up though.
Modelling
What's a model?
A mathematical structure that approximates a part of the world. (Hopefully the part that caused your data.) Writing a model out in equations or programs can make it completely precise (and this allows us to computerise it). A model summarises, simplifies, unifies, and guides. Occasionally it surpasses.
Models are intentionally fake and smooth toys. This is because adding too much detail takes too much time and computing to be useful, and makes it impossible to make general claims, and actually prevents you from understanding the thing at hand. ("Can't see the wood for the trees.")
A model's abstraction allows us to see the unity of seemingly unrelated problems (for instance, magnetisation, the changes in states of matter, and urban riots are all explained by just one kind of model, criticality theory). The brain of the C. elegans worm, the US power grid, and the film collaborations are all very well described by one kind of mathematical object, a "small-world network". And many phenomena fall under the same "power law" distribution and can be said to share a deep structure.
A statistical model is one which admits that it's not going to get the exact right answer every time (or any time) but which offers a good approximation to an uncertain world, by giving a weighted spread of possible values for a given input.
In general, even when we call our model "highly predictive", we do not predict the future; rather we're reducing how wrong we are about the future.
Models are intentionally fake and smooth toys. This is because adding too much detail takes too much time and computing to be useful, and makes it impossible to make general claims, and actually prevents you from understanding the thing at hand. ("Can't see the wood for the trees.")
A model's abstraction allows us to see the unity of seemingly unrelated problems (for instance, magnetisation, the changes in states of matter, and urban riots are all explained by just one kind of model, criticality theory). The brain of the C. elegans worm, the US power grid, and the film collaborations are all very well described by one kind of mathematical object, a "small-world network". And many phenomena fall under the same "power law" distribution and can be said to share a deep structure.
A statistical model is one which admits that it's not going to get the exact right answer every time (or any time) but which offers a good approximation to an uncertain world, by giving a weighted spread of possible values for a given input.
In general, even when we call our model "highly predictive", we do not predict the future; rather we're reducing how wrong we are about the future.
Why does data leave us uncertain?
Because
- it is always incomplete (small samples, few features, physical limits)
- it is usually an indirect reflection of the thing of interest. (proxies, latency)
- it is noisy (measurement error, data corruption, unknown processes)
- it always has some risk of being fabricated.
- it is often ambiguous.
- of the fundamental nature of inductive thought: you can never be sure via sampling.
When can we model?
In a great paper reflecting on the Great Recession, Lo and Mueller give a taxonomy of uncertainty (in the course of arguing that economists mistook themselves as having physicists' luck, a tractable domain:
We can model well when we are in situations 1 to 3; and we can model a bit, defensively, in situation 4.
- "Complete certainty". You are in a Newtonian clockwork universe with no residuals, no observer effects, utterly stable parameters. So, given perfect information, you yield perfect predictions.
- "Risk without uncertainty". You know a probability distribution for an exhaustive set of outcomes. No statistical inference needed. This is life in a hypothetical honest casino, where the rules are transparent and always followed. This situation bears little resemblance to financial markets.
- "Fully Reducible Uncertainty". There is one probability distribution over a set of known outcomes, but parameters are unknown. Like an honest casino, but one in which the odds are not posted and must therefore be inferred from experience. In broader terms, fully reducible uncertainty describes a world in which a single model generates all outcomes, and this model is parameterized by a finite number of unknown parameters that do not change over time and which can be estimated with an arbitrary degree of precision given enough data. As sample size increases, classical inference brings this level down to level 2.
- "Partially Reducible Uncertainty". The distribution generating the data changes too frequently or is too complex to be estimated, or it consists in several nonperiodic regimes. Statistical inference cannot ever reduce this uncertainty to risk. Four sources:
(1) stochastic or time-varying parameters that vary too frequently to be estimated accurately;
At this level of uncertainty, modeling philosophies and objectives in economics and finance begin to deviate significantly from those of the physical sciences... model-building in the social sciences should be much less informed by mathematical aesthetics, and much more by pragmatism in the face of partially reducible uncertainty.
(2) nonlinearities too complex to be captured by existing models, techniques, and datasets;
(3) non-stationarities and non-ergodicities that render useless the Law of Large Numbers, Central Limit Theorem, and other methods of statistical inference and approximation;
and (4) the dependence on relevant but unknown and unknowable conditioning information. - "Irreducible uncertainty". Ignorance so complete that it cannot be reduced using data: no distribution, so no success in risk management. Such uncertainty is beyond the reach of probabilistic reasoning, statistical inference, and any meaningful quantification. This type of uncertainty is the domain of philosophers and religious leaders, who focus on not only the unknown, but the unknowable.
We can model well when we are in situations 1 to 3; and we can model a bit, defensively, in situation 4.
What can modelling do?
- summarise data
- predict new data
- simulate reality
To predict new data is to use a model to summarise future data. (Since a model is also a compressed description of a dataset.)
To simulate reality requires you to infer actual structure and true parameters: to infer these is to predict that future data will confirm your estimates of them, and the inference is also a prediction that repeat experiments will find the same parameters, if you factor out noise.
Model of modelling
All human activities can be described by five components: data, prediction, judgment, action, and outcomes. A visit to the doctor leads to:
1) x-rays, blood tests, monitoring (data),
2) diagnosis: “if we administer treatment A, then we predict outcome X, but if we administer treatment B, then we predict outcome Y” (prediction),
3) “given your age, lifestyle, and family status, I think you might be best with treatment A...” (judgment);
4) administering treatment A (action), and
5) full recovery with minor side effects (outcome).
As machine intelligence improves, the value of human prediction skills will decrease because machine prediction will provide a cheaper and better substitute, just as machines did for arithmetic...
Why is my model wrong?
Hoo boy.
First, recall that the "error" of model outputs denotes the uncertainty surrounding a number, not the blunders. Error in this sense is routine and non-blameworthy. There are two classes of error:
1. Systematic uncertainties:
We can split systematics into two, model error and parameter error 134:
First, recall that the "error" of model outputs denotes the uncertainty surrounding a number, not the blunders. Error in this sense is routine and non-blameworthy. There are two classes of error:
1. Systematic uncertainties:
- are due to problems with calibrating the data collection process, or due to the modelling approach
- are usually correlated with previous measurements
- occur when a theory is not yet mature.
- can arise from real fluctuations (e.g. random quantum processes),
- are uncorrelated with previous measurements,
- follow a well-developed theory;
We can split systematics into two, model error and parameter error 134:
Model error
- Model is approximation
- Best fit sucks
- Black swan
- Unlucky with training set: fits wrong model by chance.
Parameter error
The incorrectness of the numbers that define the model, given that the model is correct.
Can be estimated by taking confidence intervals for each parameter; using bootstrapping to obtain your parameter estimates; or by Bayesian estimation of parameters, which price in such uncertainty automatically.
- Concept drift: the population values changed since you collected your data.
- Bad estimation
- via Sampling error
- via Systematic measurement error
- via numerical errors (in discretization, truncation, or round-off)
Can be estimated by taking confidence intervals for each parameter; using bootstrapping to obtain your parameter estimates; or by Bayesian estimation of parameters, which price in such uncertainty automatically.
Stochastic error
Everything's fine, you just got unlucky.
Stochastic errors are neat and tidy: assumed to have a mean value of zero, to be uncorrelated with the predictor variables, to have constant variance, and to be uncorrelated with their own past values. Well-specified and easy to forecast (using simulation).
Stochastic errors are neat and tidy: assumed to have a mean value of zero, to be uncorrelated with the predictor variables, to have constant variance, and to be uncorrelated with their own past values. Well-specified and easy to forecast (using simulation).
My model used to be right; why is it wrong now?
- It was overfitted to an imperfectly representative training set.
- The population has changed ("Concept drift")
- Your analysis environment has changed ("Data drift")
What causes data drift?
- Structural drift: the source schema is changed
- Semantic drift: the data is constant but its meaning changes.
- Infrastructure drift: breaking change in an update to some part of pipeline.
Machine learning
Why is ML so hot right now?
Because of a burst of successes in previously intractable tasks (which make money, or should eventually make money).
Why the burst of successes?
Substantially just because we have millions of times more data now, a wonderful architecture for dealing with it quickly, and ways of using it without a human having to touch it.
Also because of steady improvements in statistical theory: e.g. nonparametric models, which don't compress away any of the information in your inputs and still don't take long to compute.
Also because of steady improvements in statistical theory: e.g. nonparametric models, which don't compress away any of the information in your inputs and still don't take long to compute.
Why are statistics and machine learning treated so differently?
Good question, since they are both just statistical modelling approaches: it's just a tribal separation. That is, the methods were developed (and reinvented) in different university departments.
One real difference is that black-box prediction, which is so often the terminal goal in ML, was heavily disparaged in stats for a long time. So a cartoon statistician aimed to infer the data-generating mechanism, while a cartoon ML engineer aimed for optimum prediction of future data. This wall is breaking down, I'm told.
One real difference is that black-box prediction, which is so often the terminal goal in ML, was heavily disparaged in stats for a long time. So a cartoon statistician aimed to infer the data-generating mechanism, while a cartoon ML engineer aimed for optimum prediction of future data. This wall is breaking down, I'm told.
Generation and discrimination
The above prediction / inference split can put into actual model terms:
- Generative model. $$p(x|\theta)$$. We think of the data as having been ``drawn from'' $p(x|\theta)$ but using the true value of $\theta$, which you don't actually know.
(AKA "sampling distribution" and "probability model for the data". You can see people gesturing towards this when they say "mechanistic, phenomenological, substantive, iconic" models.) - Discriminative models: ("empirical, data-driven, descriptive" models).
What's the difference between inference and prediction?
In a sense they're not different: to infer (parameters) is to predict what new data will look like, and is also to predict that repeat experiments will find similar parameters. But conventionally, inference is an attempt to find the actual way that the data were generated, not just an empirically adequate tool that gets the input-output pairs correct enough.
The question for inference is "how exactly were these data generated?", where prediction just wants a decent answer to "what output will new inputs result in?". Leaping from data to world, or from data to more data.
The question for inference is "how exactly were these data generated?", where prediction just wants a decent answer to "what output will new inputs result in?". Leaping from data to world, or from data to more data.
What sorts of machine learning are there?
That's a poorly defined question, Gavin. We can classify ML systems in a few ways: by the sort of data they use; by the abstract approach their algorithm takes; by the structure of the task they're solving, or by the literal task ("speech recognisers" or "car drivers").
By nature of inputs
Unsupervised learning
Clustering: take unlabelled inputs, give discrete outputs.
- Centroid-based:
- Density-based:
- Distribution-based:
- Hierarchical:
Supervised learning
- Classification: labelled inputs, discrete output
Reinforcement learning
Kind of in-between.
By nature of output
- Classification: gives a discrete output over a set of groups
e.g.: logistic regression, linear SVM, naïve Bayes, classification tree, collaborative filtering: KNN, alternating least squares (ALS), non-negative matrix factorization (NMF) - Regression:
e.g.: generalized linear models (GLMs), regression tree - Clustering, discrete output for unknown groups
e.g.: k-means, DBSCAN. - Density estimation, output the distribution of inputs.
- Dimensionality reduction: Singular value decomposition, Principal Components analysis
- optimization: stochastic gradient descent, L-BFGS
What's the best algorithm?
There exists a sweeping and powerful proof that there is no such computable thing.
In practice, the most competitive algorithm over a range of well-defined problems are neural networks (replacing the gradient boosting machines which ruled before them).
In practice, the most competitive algorithm over a range of well-defined problems are neural networks (replacing the gradient boosting machines which ruled before them).
What is it that machines learn?
Not "knowledge" or "tasks"; each model is an instance of some computational structure, whether:
Finding a function (a pairing machine like an equation) is by far the most common aim. Learning is usually "figuring out an equation to solve a specific problem based on some example data”.
- Functions
- Rulesets (ILP)
- State machines
- Grammars
- Problem solvers
Finding a function (a pairing machine like an equation) is by far the most common aim. Learning is usually "figuring out an equation to solve a specific problem based on some example data”.
What's deep about deep learning?
There's a boring and an exciting version. The boring reading is just that deep NNs have a big gap between the input and output layer: more hidden layers mean deep.
The exciting reading is when we take recent successes to hint at a fundamental mechanism of all learning: successive abstractions, one per layer, until a clear signal rests atop the network: a newlyborn concept.
The exciting reading is when we take recent successes to hint at a fundamental mechanism of all learning: successive abstractions, one per layer, until a clear signal rests atop the network: a newlyborn concept.
What's the difference between machine learning and data mining?
Surprisingly, they're not totally well-defined terms. But when they are being explicitly distinguished:
- ML is pure statistical learning: you hand it input-output pairs and tweak until your function is approximated.
- DM is learning over well-understood domains, where you can design your algorithms substantially.
How do you design learners?
You need to write the output model in a language the computer understands (model representation),
you need to encode the examples in a way the computer understands (data representation),
you need an unambiguous rule for distinguishing good models from bad ones (evaluation function),
and you need a way of picking the best hypothesis in the model language (optimisation function).
you need to encode the examples in a way the computer understands (data representation),
you need an unambiguous rule for distinguishing good models from bad ones (evaluation function),
and you need a way of picking the best hypothesis in the model language (optimisation function).
How shall I represent the model?
First, what do you know? The representation you choose limits the knowledge you can encode into the learner. If we have a lot of knowledge about what makes examples similar, you should use 'instance-based methods'. If we have knowledge about probabilistic dependencies, graphical models. If we have knowledge about the strict conditions involved, use first-order logic.
- instance: no generalisation, just compare new to all previous, in memory (e.g. k-nearest neighbors)
- Hyperplane-based methods form a linear combination of the features per class and predict the class with the highest-valued combination.
- Decision trees test one feature at each internal node, with one branch for each feature value, and have class predictions at the leaves.
How do I avoid overfitting?
- Add a term to the eval function (Regularisation):
- Tikhonov regularization: penalize complex functions
- Ivanov regularization: constrain the hypothesis space, either in the functional form or by adding constraints to the
- Simple significance test before and after, before adding new features
Isn't trying millions of hypotheses going to find nonsense coincidences?
Yes. A grid search is the ultimate in multiple testing risk.
We have to control the false discovery rate (fraction of falsely accepted non-null hypotheses).
Bonferroni.
Why is machine learning hard?
Because of the combinatorial explosion, or "curse of dimensionality".
And also in the process: the size of the failure space is arguably the square of software engineering's (already enormous) failure space.
And also in the process: the size of the failure space is arguably the square of software engineering's (already enormous) failure space.
What is the curse of dimensionality?
"most of the volume of a high-dimensional orange is in the skin, not the pulp."
Generalizing correctly becomes exponentially harder as the dimensionality grows, because a fixed-size training set covers a dwindling fraction of the input space.
An example from Pedro Domingos:
Say you have a vast, vast training set: a trillion rows and a hundred columns (which all just say "Yes" or "No" about the feature they're representing). Your vast training set still only covers a tiny fraction, 0.0000000000000000001%, of the whole input space:
$$ \text{Number of possible inputs} = 2^{100} = 1.3 x 10^{30}.$$ $$ 1 \text{trillion} = 1 x 10^{12} $$ $$ \text{coverage} = 1 x 10^{12} / 1.3 x 10^{30} = 1^{-18}th \text{of all possible examples} $$ * blessing of non-uniformity: examples are usually not spread uniformly throughout the instance space, but are concentrated near a lower-dimensional manifold. For example, k-nearest neighbor works quite well for handwritten digit recognition even though images of digits have one dimension per pixel, because the space of digit images is much smaller than the space of all possible images.
An example from Pedro Domingos:
Say you have a vast, vast training set: a trillion rows and a hundred columns (which all just say "Yes" or "No" about the feature they're representing). Your vast training set still only covers a tiny fraction, 0.0000000000000000001%, of the whole input space:
$$ \text{Number of possible inputs} = 2^{100} = 1.3 x 10^{30}.$$ $$ 1 \text{trillion} = 1 x 10^{12} $$ $$ \text{coverage} = 1 x 10^{12} / 1.3 x 10^{30} = 1^{-18}th \text{of all possible examples} $$ * blessing of non-uniformity: examples are usually not spread uniformly throughout the instance space, but are concentrated near a lower-dimensional manifold. For example, k-nearest neighbor works quite well for handwritten digit recognition even though images of digits have one dimension per pixel, because the space of digit images is much smaller than the space of all possible images.
Programming
Why do I need to code? I just want to analyse data.
Well - you accept you must use software. And you are accustomed to using other people's software.
But when your task is in any way unusual, or when you're a hotshot who needs more performance than the Enterprise people shovel at you, or when you need to glue together several other pieces of software, or when you want more than just one-off answers - i.e. a regular report, or millions of split-second decisions, or a giant real-time pipeline, or a whole weak AI of your very own - then you will be coding (or hiring coders).
Minimally, code is glue for systems: take input from tool #1, change the format a little, give to tool #2. We call this scripting.
Maximally, code is the heart of your comparative advantage and the reason you haven't been steamrolled into the competitive sump yet. We call this application development. An app unifies a whole process: networking, scraping and web API abuse, cleaning, crunching, graphics, mailing reports, whatever.
If you program your way through a data problem, you gain much power and efficiency. You:
But when your task is in any way unusual, or when you're a hotshot who needs more performance than the Enterprise people shovel at you, or when you need to glue together several other pieces of software, or when you want more than just one-off answers - i.e. a regular report, or millions of split-second decisions, or a giant real-time pipeline, or a whole weak AI of your very own - then you will be coding (or hiring coders).
Minimally, code is glue for systems: take input from tool #1, change the format a little, give to tool #2. We call this scripting.
Maximally, code is the heart of your comparative advantage and the reason you haven't been steamrolled into the competitive sump yet. We call this application development. An app unifies a whole process: networking, scraping and web API abuse, cleaning, crunching, graphics, mailing reports, whatever.
If you program your way through a data problem, you gain much power and efficiency. You:
- Can liberate the task from proprietary software. Done right, this yields 1) performance, 2) actual customisability, 3) massive cost savings. 201
- Horizontal scaling. The corporate IT giants (SAS, Oracle) can't touch the cost-effectiveness of open source HPC / distributed analysis: when your need grows, you can just bolt on a new server. Commercial distributed tools will come, but expensively. Hadoop is free, except for the 100 servers you have to buy.
- Utterly flexible. Many of the best tools are just code libraries. (As opposed to full apps.) Can do unprecedented tasks.
- Your programs can do without the overhead of a GUI.
- Writing your analysis as a script means that you can share the work very easily, which means division of labour, reproducible results, and easy automation of even very intense quantitative work.
Code as enquiry
But there's a larger point: coding is a novel way of thinking in general. Yes, it is like maths - but testable, causal, interactive.
A programming language is "how you tell a computer what to do". But before that it's a way to express ideas and get push back from a rational oracle. (It's not reality that's pushing back, of course. You don't know if they're true, but you know if they are clear, if they could even possibly be true, if you are not completely fooling yourself.)
Consider the Bible, or Karl Marx's work, or Sigmund Freud's work. These are rammed full of invalid and unsound ideas - but they are beautiful, unified, and powerful, so they proved persuasive to billions of people. Human language offers no easy test of consistency, no way of really precisely connecting idea to idea. We have had only hard, piecemeal, irreplicable interpretation.
To see what's added by code, here's a thought experiment: Imagine the economic value of a line-by-line description, in English, of the Linux kernel. It would be nothing compared to the billions of dollars of value the kernel has created or saved. 200
The computability of source code is a side effect of its clarity. Code is testable thought.
A programming language is "how you tell a computer what to do". But before that it's a way to express ideas and get push back from a rational oracle. (It's not reality that's pushing back, of course. You don't know if they're true, but you know if they are clear, if they could even possibly be true, if you are not completely fooling yourself.)
Consider the Bible, or Karl Marx's work, or Sigmund Freud's work. These are rammed full of invalid and unsound ideas - but they are beautiful, unified, and powerful, so they proved persuasive to billions of people. Human language offers no easy test of consistency, no way of really precisely connecting idea to idea. We have had only hard, piecemeal, irreplicable interpretation.
To see what's added by code, here's a thought experiment: Imagine the economic value of a line-by-line description, in English, of the Linux kernel. It would be nothing compared to the billions of dollars of value the kernel has created or saved. 200
The computability of source code is a side effect of its clarity. Code is testable thought.
R or Python or Java or Scala?
This decision is really not as important as it looks. Scala and Python are beautiful to write. Java is everywhere (and lets you flick between DS and trad software engineering jobs). R is academically cutting-edge.
Alright, here's a deeper take - but you must add your own weights to the columns:
Whatever you do, learn regex!
Alright, here's a deeper take - but you must add your own weights to the columns:
Whatever you do, learn regex!
Data janitoring
Pieces on Medium professing "How to Learn Data Science in 19 seconds" usually fail to mention that ~50% of the work is gathering and cleaning data, one column at a time. Which is no damn fun at all, obviously.
What is big data?
It's like, so 2013.
Practically speaking, 'big data' is any dataset which cannot fit in memory on an expensive computer. More often, 'big data' refers to the use of that data: i.e. it is cheap, mass surveillance of private citizens by businesses and governments.
Practically speaking, 'big data' is any dataset which cannot fit in memory on an expensive computer. More often, 'big data' refers to the use of that data: i.e. it is cheap, mass surveillance of private citizens by businesses and governments.
Whoa, that doesn't sound disruptive or transformative at all!
Oh it is - just not in your favour. A model is often dangerous if it is wrong, and sometimes dangerous if it is right.
Cathy O'Neil writes persuasively about perverse decision systems 301; from her I distilled this list of warning signs:
Opacity
Scale
Damage
Cathy O'Neil writes persuasively about perverse decision systems 301; from her I distilled this list of warning signs:
Opacity
- Is the subject aware they are being modelled?
- Is the subject aware of the model's outputs?
- Is the subject aware of the model's predictors and weights?
- Is the data the model uses open?
- Is it dynamic - does it update on its failed predictions?
Scale
- Does the model make decisions about many thousands of people?
- Is the model famous enough to change incentives in its domain?
- Does the model cause vicious feedback loops?
- Does the model assign high-variance population estimates to individuals?
Damage
- Does the model work against the subject's interests?
- If yes, does the model do so in the social interest?
- Is the model fully automated, i.e. does it make decisions as well as predictions?
- Does the model take into account things it shouldn't?
- Do its false positives do harm? Do its true positives?
- Is the harm of a false positive symmetric with the good of a true positive?
A Hippocratic Oath of Modeling
After the financial meltdown in 2008, the ex-quant Emanuel Derman came up with this:
Precisely because it is a bit overheated, it could catch on.
- I will remember that I didn’t make the world, and it doesn’t satisfy my equations.
- Though I will use models boldly to estimate value, I will not be overly impressed by mathematics.
- I will never sacrifice reality for elegance without explaining why I have done so. Nor will I give the people who use my model false comfort about its accuracy. Instead, I will make explicit its assumptions and oversights.
- I understand that my work may have enormous effects on society and the economy, many of them beyond my comprehension.
Precisely because it is a bit overheated, it could catch on.
Enough deep social implications: get to the boring bit
The "data life cycle", which you might be lucky enough to control, depending on your organisation size:
- Data capture.
- Data maintenance. Busywork: any processing that doesn't generate value itself (movement, integration, cleansing, enrichment, extract-transform-load). Also calculating derived values like (Net revenue = Gross revenue - fixed costs - variable costs x units).
- Data synthesis. To creation values via some inductive logic: predictions or inferences.
- Data usage. Use in object-level tasks.
- Data publication. To send data outside the org. Includes data breaches.
- Data archival. To backup and then remove data from production environments.
- Data purging. To remove every copy from the org.
What do people mean by "unstructured" data?
It's another surprisingly vague term. It means something like "data without a schema, or normalisation, or metadata, or labelling as a good or bad outcome". Anything you couldn't analyse on a spreadsheet. Text corpuses are a good example: the meaning is in there somewhere, but "structured" (nonprobabilistic) methods won't help you much.
Or: Structured data is joined-up data: relations are known, duplicates have been taken out, absolute timings are given, connections to other rows are graphed.
Or: Structured data is joined-up data: relations are known, duplicates have been taken out, absolute timings are given, connections to other rows are graphed.
When do you have to structure data?
When performance (network latency or model training speed or model accuracy) is more important than the cost.
What are the downsides of more data?
- If you're just adding features but not rows, then you might be damaging your model with overfit and redundancy.
- If most values are zero then you have a sparsity problem. (Yes, "zero" or "N/A" is still data.)
- If it takes you above the 64GB sweet spot, so it doesn't fit in one computer's RAM, and doesn't gain much from parallelisation. Much harder to manipulate, even in these halcyon days of Spark and Sqoop.
- Some datasets are fantastically expensive, and you don't necessarily know that it will even help before you buy.
How much harder does the distributed bit make everything?
Since 2006, the launch of MapReduce, not that much. Since 2014, the launch of Spark, only as hard as functional programming is.
One of the jarring things about Hadoop development, speaking as a C21st programmer, is the return to massive waits between edit/compile/debug cycles (like, a 5 minute wait even using test data). This is the other price (besides your $100,000 Azure bill.)
One of the jarring things about Hadoop development, speaking as a C21st programmer, is the return to massive waits between edit/compile/debug cycles (like, a 5 minute wait even using test data). This is the other price (besides your $100,000 Azure bill.)
Recommended reading
Don't know higher maths, don't know code
Hell mode.
If you're like me, you'll need qualitative meaning first, to get you fired up: Gleick's The Information and Nilsson's Quest for Artificial Intelligence, Hofstadter's Goedel, Escher, Bach, Floridi's Blackwell Guide to the Philosophy of Computation, Howson's Scientific Reasoning, O'Neil's Weapons of Math Destruction, Domingos' Master Algorithm. Then the real work begins:
If you're like me, you'll need qualitative meaning first, to get you fired up: Gleick's The Information and Nilsson's Quest for Artificial Intelligence, Hofstadter's Goedel, Escher, Bach, Floridi's Blackwell Guide to the Philosophy of Computation, Howson's Scientific Reasoning, O'Neil's Weapons of Math Destruction, Domingos' Master Algorithm. Then the real work begins:
- Start with Python: Zed Shaw's Learn the Hard Way will get you moving, if you do as he tells you. Learn Python 3; you probably won't have much Python2 legacy code to handle.
- You must read other people's code to improve. Try a gamified site like CodeWars, which shows you elegant solutions only after you sweat out a dreadful hack.
- This is the nicest series of maths videos I've ever seen. Constant clicking of concepts into place.
- Once you are comfortable with basic abstraction, work through Downey's Think Stats.
- I enjoyed Blais' Statistical Inference for Everyone too.
Don't know higher maths, but can code
Danger zone.
- Work through Downey's Think Stats, Think Bayes and Davidson's Probabilistic Programming for Hackers.
- Grus' Data Science from Scratch will make you implement all kinds of cool statistical machines, which gives you an edge over even the highly mathematised people.
- Efron and Hastie's Computer Age Statistical Inference is a treat. It will persuade you that statisticians are presently being plagiarised and shortchanged.
- Ross' First Course in Probability</i>
- The Cambridge Maths for the Natural Sciences workbook is a focussed fave. Similarly, Meyer's Mathematics for Computer Science.
- Tom Mitchell's Machine Learning is old but clear. And being old is good: cuts through hype and shows what is not new at all.
- Oehler's A First Course in Design and Analysis of Experiments
- Mattuck's Intro to Analysis, chapters 1 - 17.
- then Strang's Linear Algebra, chapters 1,2,3,6 at least.
- A partisan pick is Etz et al's How to Become a Bayesian.
Know higher maths, can't code
A reach ten times your grasp.
- Cady's >Handbook is designed especially for you, in that case. I like his scepticism and choice of tools n topics.
- Learn Python the Hard Way might be too slow. Try Sargent & Stachurski's Quantitative Economics (it's more broadly applicable than it sounds) or just dive into Grus.
- Neural Networks and Deep Learning is a great read.
- Jaynes' unfinished masterwork, The Logic of Science will tie together acres of mathematical ground. Start by reading the bitchy footnotes!
- Kleinberg & Tardos is the nicest intro to algos.
Know higher maths, can code
Well what are you waiting for?
- Chen's 120 Data Science Interview Questions gives you a good sense of how the field actually unfolds in business settings. And how brutal it's going to be if you interview in America.
- Mackay's Information Theory, Inference, and Learning Algorithms is really very beautiful.
- Pearl's Causality is groundbreaking, exciting, and clear
- Shalizi's Advanced Data Analysis is a wonderful read.
- Blum et al, Foundations of Data Science is maybe the first heavy textbook that focusses entirely on the core problems of the mishmash that is DS: hyper dimensionality is chapter 1, complexity theory, Bonferroni ghosts...</i>
- Everybody always recommends Hastie and Tibshirani, but Mackay's my guy.
- Bishop's Pattern Recognition is similarly hyped. It is synoptic and rigorous but hard work.
- Then there are the tool books, but you'll have no problem with those
Full list here. All books: I don't care for MOOCs or Youtube series. You can ignore all Medium posts on the matter (or any matter), with the exception of @akelleh, which you must read.
Glossary
- algorithm: a recipe for computing something. Programs are instances of an algorithm, like you're an instance of the human genome.
When people talk about "ML algorithms" they tend to mean learners. 404 - machine learning: "LEARNING = REPRESENTATION + EVALUATION + OPTIMIZATION." 405
- learner: an inductive program that takes in examples and outputs a model.
- model: a program that predicts outputs from examples. (see also classifier, regressor).
- data scientist: an inductive program that takes a vaguely posed problem, plus a dataset, and outputs a learner.
- examples: rows. (AKA record, case, instance, observation, data point, 'sample' 403.)In most usecases, examples are tuples of scalars.
- features: columns. (AKA attributes, explanatory variables, independent variables, predictors, manipulated variables, inputs, exposure, risk factors, regressors, variates, covariates.)
- output: (AKA response variable, dependent variable, predicted, explained, experimental, outcome, regressand, label.)
- index: row names
- schema or header: column names
- training set: the examples given to the learner
- test set: the examples given to the model
- contamination: using test data at any stage during building the model
- dimensionality: the number of features you give to the learner.
- classifier: a model that takes in numbers and gives you a type in response.
- regressor: a model that takes in numbers and gives you a number in response.
- overfitting: hallucinating a classifier; putting too much trust in flukes or mistakes in the training set. (encoding the noise)
- bias: underfitting. a learner’s tendency to consistently learn the wrong thing.
- variance: overfitting. a learner’s tendency to learn random things and not the real signal
- bias–variance tradeoff: you can't both finding a function that generalises v finding a function that captures all the signal of the training set. Simple functions mean bias, complex functions mean variance.
- hypothesis space: the set of classifiers that a learner can learn. Determined by representation choice (and by the optimisation function, if the evaluation function has multiple optimal choices).
- theory: a machine that answers a class of questions. 3
if praise is given to those who have determined the number of Platonic solids... how much better will it be to bring under mathematical laws human reasoning, the most excellent and useful thing we have?
- Gottfried von Leibniz
The learning process may be regarded as a search for a form of behaviour which will satisfy the teacher.
- Alan Turing
Inspired by this long list of things that separate a fresh programmer from an actual engineer. 2.
See also
- Though it maybe won't remain an art for long.
- That Programmer Competency Matrix is aggressively written: it is exasperated with poor job applicants. But when I was a clueless beginner, I found it helpful for someone to just tell me what exactly I was missing, even if that was a long list and 10 years' work to go.
- This quotation isn't very relevant, I just think it's bad ass. It is from Judea Pearl's acceptance speech for the Lakatos Award.
- It's easy to say the reason is just pay, but that's circular: data scientists are paid more in prospect, because of the buzz around them, before they get anything done in a given organisation.
I suppose the real productivity gains of e.g. Hammerbacher and LeCun could have caused the hype... - "70%" :
Estimate quality: OK, a Spiegelhalter (2*).
Sample size: 250. Not randomised.
Source: O'Reilly.
Importance to argument: High.
- The other very distinct job is of course "data engineer". But those are already distinguished properly in the job market, for the obvious reason that your cluster will crash and burn if you hire the wrong one of them.
- Man this is a great site.
- New methods? Newer than what?
Newer than pre-computer and tiny-sample statistical inference theory. You can get a sense for how new ML is from Bishop (2006). That book only mentions very important papers. And, in fact, summarising its bibliography gets us a median year of 1995 and a mode year 1999. So even ignoring the disproportionately important last ten years, it is a very young field. - The hyperparameters of a data scientist are mathematical rigour, coding ability, misanthropy and pay.
- Kaggle is just feature play and modelling. (So, if this Process defines the job 'data scientist' well, then Kaggle is just a ML platform, not a data science platform, as labelled.)
- Also called statistical error or random error, but those names are vague to me. I suppose they get called statistical errors because you can use pure stats to detect and control for them, unlike systematic error.
- Model error and parameter error seem like they could be unified: if a model error is just a sufficiency large (number of) parameter errors. Making bad assumptions about e.g. auto-correlation between your features seems like just parameter error, while using the wrong distribution is model error.
This hinges on whether models are just big collections of parameters, I guess. - which billions do not even count the main value Linux creates, externalities: induced demand for other software, and coerced quality from MS and Apple.
- Writing analysis scripts is much less heavy than real development, where it'd be absurdly expensive to 'roll your own' very often.
- Following recent convention, she calls the systems 'algorithms'. But it isn't the inaccurate or static abstract program that does the harm, but credulous lack of validation of the program. They only do harm when they are allowed to make or guide decisions.
See also "recommender systems", "info filtering systems", "decision-making systems", "credit scoring". - Currently called feature extraction, ambiguously IMO.
- If you care, you can add further dimensions: redundant, transformable, measurable for a less readable 64 classes.
- Please don't use "sample" to mean a single data point; it serves us well as "a collection of data points".
- Though of course even using a fitted linear regression model is algorithmic: take the given value x, multiply by its coefficients, add the intercept, return prediction.
- This is Pedro Domingos' stark and good account, but it is classic: Tom Mitchell's 20 year old classic explains things the same way.