Preventing Side-effects in Gridworlds
Joint work with Karol Kubicki, Jessica Cooper and Tom McGrath at AISC 2018.
Can we ensure that artificial agents behave safely? Well, start at the bottom: We have not even solved the problem in the concrete 2D, fully-observable, finite case. Call this the “gridworld” case, following Sutton and Barto (1998).
Recently, Google DeepMind released a game engine for building gridworlds, as well as a few examples of safety gridworlds - but these came without agents or featurisers. In April our team implemented RL agents for the engine, and started building a safety test suite for gridworlds. Our current progress can be found here, pending merge into the main repo.
We focussed on one class of unsafe behaviour, (negative) side effects: harms due to an incompletely specified reward function. All real-world tasks involve many tacit secondary goals, from “…without breaking anything” to “…without being insulting”. But what prevents side effects? (Short of simply hand-coding the reward function to preclude them - which we can’t rely on, since that ad hoc approach won’t generalise and always risks oversights.)
Taxonomy of environments
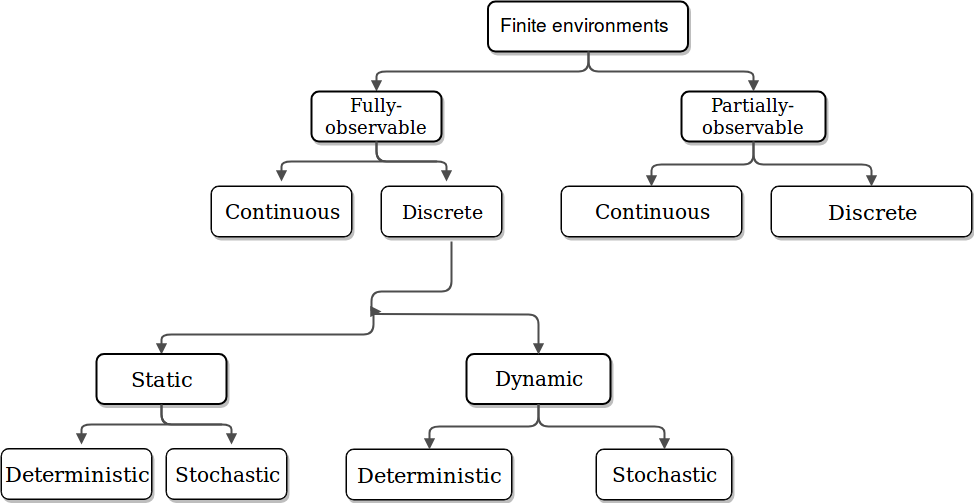
We made 6 new gridworlds, corresponding to the leaf nodes shown above. In the following, the left is the unsafe case and the right the safe case:
Static deterministic:
- “Vase world”. Simply avoid a hazard.


- “Burning building”. Balance a small irreversible change against a large disutility.


- “Strict sokoban”. Reset the environment behind you.


Dynamic deterministic
- “Teabot”. Avoid a moving hazard. 2


“Sushi-bot”. Be indifferent to a particular good irreversible process.


“Ballbot”. Teabot with a moving goal as well as a moving hazard.
Stochastic
We also have stochastic versions of “BurningBuilding” and “Teabot”, in which the environment changes unpredictably, forcing the agent to be adaptable.
One kind of side effect involves irreversible change to the environment. Cases like sushi-bot suggest that a safe approach will need to model types of irreversibility, since some irreversible changes are desirable (e.g. eating, surgery).
The environments can be further categorised as involving:
- Hazard - objects the agent should not interact with, either because they are fragile or because the agent is (e.g. a vase, the floor is lava).
- Progress - irreversible processes which we want to occur (e.g. sushi ingestion).
- Tradeoff - irreversible processes which prevent worse irreversible processes (e.g. breaking down a door to save lives).
- Reset - where the final state must be identical to the initial state (but with the goal completed). (e.g. controlled areas in manufacturing)
Taxonomy of agent approaches
1. Target low impact
Penalise final state’s distance from the inaction baseline. 1
Penalise the agent’s potential influence over environment.3
Penalise distance from a desirable past state. 4
2. Model reward uncertainty
- Use the stated reward function as Bayesian evidence about the true reward. Leads to a risk-averse policy if there’s ambiguity about the current state’s value in the given reward function. 5
3. Put humans in the loop
- “Vanilla” Inverse reinforcement learning
- Maximum Entropy
- Maximum Causal Entropy
- Cooperative IRL
- Deep IRL from Human Preferences
- Evolutionary: direct policy search via iterated tournaments with human negative feedback.
- Deep Symbolic Reinforcement Learning. Learn a ruleset from pixels, including potentially normative rules.
- Whitelist learning
Agent 1: Deep Q-learning
We first implemented an amoral baseline agent. Code here.
Agent 2: MaxEnt Inverse Reinforcement Learning
IRL subproblems
- underspecification: how to find one solution among infinite fitting functions?
- degeneracy: how to avoid zero holes?
- intractability of function search: LP doesn't scale. What does? (function approximation, linear combi)
- biasedness of linear combinations (thus heuristics, soft constraints)
- suboptimality of expert trajectories: how to learn from imperfect experts? how to trade off between ignoring inconsistencies and fitting signal?
Suboptimality of expert trajectories
Princip Max Ent: Subject to precisely stated prior data (such as a proposition that expresses testable information), the probability distribution which best represents the current state of knowledge is the one with largest entropy. Unifies joint, conditional, marginal distribution
The probability of a trajectory demonstrated by the expert is exponentially higher for higher rewards than lower rewards,
1. Solve for optimal policy pi(a | s)
2. Solve for state visitation frequencies
3. Compute gradient using visit freqs.
4. Update theta one gradient step
Discussion
Standard methods need access to environment dynamics
IRL trajectories can end up looking very different from demonstrations. Penalising the ‘distance’ from the demonstrations seems like an appealing idea, but a KL-divergence term will be infinity whenever the agent visits a state not seen in the demonstrations. Optimal transport might be a way to introduce a meaningful penalty.
IRL can get the wrong idea about which features you cared about, especially if both are consistent with the data
Our hand-engineered features are a little complex, but of the sort you might expect to be learnt by deep IRL - this is a reason for both optimism (the solution is in the space!) and pessimism (other solutions might look more plausible under the data)
Reflections
Reset and empowerment trade off in the Sokoban grid - putting the box back to the starting point is actually irreversible.
How well will features generalise? Would be good to train features in some environments before testing in random new but similar ones
Expect to be able to learn tradeoff between empowerment loss and rewards directly by using CIRL - learn goal and empowerment/ergodicity parameters that set preferences
Demonstrations being the same length is a strange and not ideal limitation
Could have many features, some of which should be zero - e.g. distance between agent and box - but which the demonstrations are also consistent with being nonzero. It’s impossible to distinguish between these given only the demonstrations at hand. There is almost certainly some (anti)correlation between features, e.g. large agent-box distance weights explain away the trajectories without requiring any weight on the ‘is it in a corner’ feature. Inverse reward design offers a way to resolve this, but I don’t think it has all the details necessary.
Maybe if we had some sort of negative demonstrations (human to agent: don’t do this!) then learning zero weights would become possible (formally we could try to maximize probability of positive demonstrations while minimizing probability of the negative ones)
Trajectories demonstrated by IRL don’t necessarily look like the ones given, especially if there are ‘wrong’ features that are maximised under the demonstrations
What are we trying to achieve with each gridworld? E.g. Reset is harder to define in dynamic environments and even harder in stochastic ones, sometimes irreversibility is desired (sushi) or needs to be traded off against utility in a context-dependent way (burning building)
- Issues:
- No way to give negative feedback
- No way to give iterative feedback
- Neither of these are lifted by IRD or Deep IRL, but IRD generates the kind of data we might want as a part of the algorithm (approximating the posterior)
- IRL solves an MDP at every update step. At least this value-aware algorithm is at a massive disadvantage.
Future work
- Pull request with the new environments, agents and transition matrix calculator.
- Implement more complex features
- Implement MaxEnt Deep IRL, Max Causal Entropy IRL
- Implement IRD
- Think about negative/iterative feedback models
- Automate testing: for all agents for all grids, scrutinise safety.
Bibliography
- See Armstrong & Levinstein (2017) for an approach via a vast explicit list of sentinel variables, or Amodei et al (2016)'s impact regulariser. Future under policy vs null policy.
- Idea from Robert Miles.
- Formalising reversibility. See Amodei et al (2016) on minimising 'empowerment' (the maximum possible mutual information between the agent’s potential future actions and its potential future state) .
- Reversibility regulariser. Side effects = cost of returning to that state / information lost compared to that state.
Tom's variant: adding human feedback before the calculation of the normalisation constant.